1 系统环境
Ubuntu 16.04 LTS
elasticsearch-6.5.4.tar.gz
logstash-6.5.4.tar.gz
kibana-6.5.4-linux-x86_64.tar.gz
工具网址:https://www.elastic.co/downloads
2 ELK介绍
Elasticsearch:是一个分布式、可扩展、实时的搜索与数据分析引擎,具有高可伸缩、高可靠等特点。基于全文搜索引擎库Apache Lucene基础之上,能对大容量的数据进行接近实时的存储、搜索和分析操作。
Logstash:数据处理引擎,能够同时从多个来源采集数据,通过过滤器解析、转换数据,最后输出到存储库Elasticsearch。
Kibana:数据分析与可视化平台,结合Elasticsearch使用,对数据进行汇总、搜索和分析,利用图表、报表、地图组件对数据进行可视化分析。
3 搭建过程
3.1 安装ElasticSearch
\1. 解压elasticsearch tar包
1 | tar -zxvf elasticsearch-6.5.4.tar.gz |

\2. 修改配置config/elasticsearch.yml,在es目录下创建data和logs文件夹
1 | path.data: /opt/apps/elk/elasticsearch-6.5.4/data |
network.host: 0.0.0.0 测试,可以添加自己的IP以限制访问;
3.启动elasticsearch服务
1 | ./elasticsearch & |
出现异常提示:不能以root用户运行elasticsearch
1 | org.elasticsearch.bootstrap.StartupException: java.lang.RuntimeException: can not run elasticsearch as root |
原因:由于elasticsearch可以接收用户输入的脚本并且执行,所以系统为了安全考虑设置了条件。
解决:root用户下创建新用户用于测试elasticsearch
1 | # 创建elk用户组 |
这时切换到elk用户,执行
1 | su elk |
切换至elk用户,再次启动 elasticsearch,出现以下错误提示
1 | ERROR: bootstrap checks failed |
原因:elasticsearch默认使用混合mmapfs/niofs目录来存储其索引,对mmap计数的默认操作系统限制可能过低,可能导致内存不足异常。
解决:切换root用户,修改内核参数vm.max_map_count
1 | # 内核参数配置文件/etc/sysctl.conf添加配置 |
切换回elk用户,重新启动elasticsearch
1 | #启动elasticsearch |
4.验证是否启动成功
curl ‘http://1270.0.1:9200'
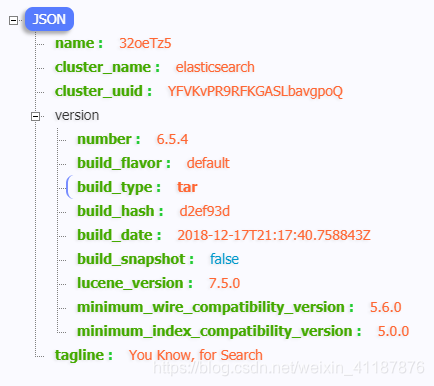 )
)
返回以上内容说明启动成功。
3.2 安装Logstash
1.解压logstash tar包
1 | tar -zxvf logstash-6.5.4.tar.gz |
Logstash Pipeline有两个必须的部分,输入和输出,以及可选部分过滤器。输入插件消费某个来源的数据,过滤器插件根据设置处理数据,输出插件将数据写到目标存储库。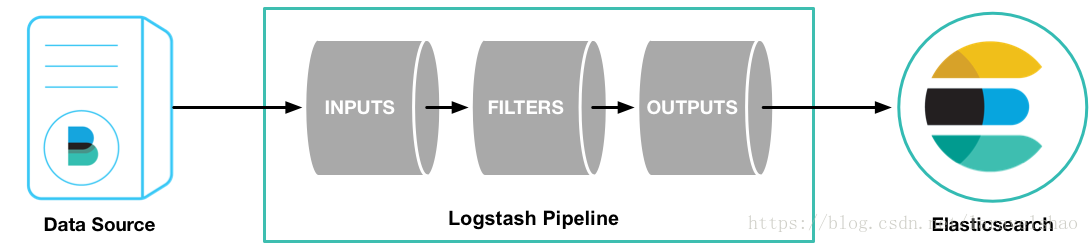
2.运行logstash最基础的pipeline
1 | bin/logstash -e 'input { stdin { } } output { stdout {} }' |
-e:可以直接用命令行配置,无需使用文件配置。当前pipeline从标准输入获取数据stdin,并把结构化数据输出到标准输出stdout。
Pipeline启动之后,控制台输入hello world,可看到对应输出。
3.安装logstash-input-beats插件
1 | ./bin/logstash-plugin install logstash-input-beats |
4.创建pipeline配置文件logstash.conf,配置端口5044监听beats的连接,并创建elasticsearch索引。
1 | input { |
5.启动logstash服务
1 | ./bin/logstash -f logstash.conf & |
输入exit退出,logstash 还在后台运行
3.3 安装Kibana
1.解压kibana tar包
1 | tar -zxvf kibana-6.5.4-linux-x86_64.tar.gz |
2.修改kibana配置
1 | #访问kibana的端口 |
3.启动kibana服务
1 | ./bin/kibana & |
4.浏览器访问确认服务启动、
http://X.X.X.X:5601 (修改成你所用内网或公网地址)
 )
)
3.4 安装Filebeat
1.解压filebeat tar包
1 | tar -zxvf filebeat-6.5.4-linux-x86_64.tar.gz |
2.配置filebeat
我们这里输出到logstash,需要添加logstash信息,注释elasticsearch信息
1 | filebeat.prospectors: |
3.测试配置
1 | ./filebeat -configtest -e |
4.导出索引模板配置文件
1 | ./filebeat export template > filebeat.template.json |
5.手动安装模板
curl -XPUT -H ‘Content-Type: application/json’ http://127.0.0.1:9200/_template/filebeat-6.1.2 -d@filebeat.template.json
6.如果已经使用filebeat将数据索引到elasticsearch中,则索引可能包含旧文档。加载 Index Pattern 后,您可以从filebeat- * 中删除旧文档,以强制 Kibana 查看最新的文档
1 | curl -XDELETE 'http://127.0.0.1:9200/filebeat-*' |
7.启动filebeat
1 | ./filebeat -e -c filebeat.yml -d "publish" & |
4 Kibana简单使用
1.访问kibana地址(http://X.X.X.X:5601)
2.Discover模块默认是没有Index Pattern,需要在 Management 模块中创建一个,这里我们创建一个 filebeat-* 的Index Pattern。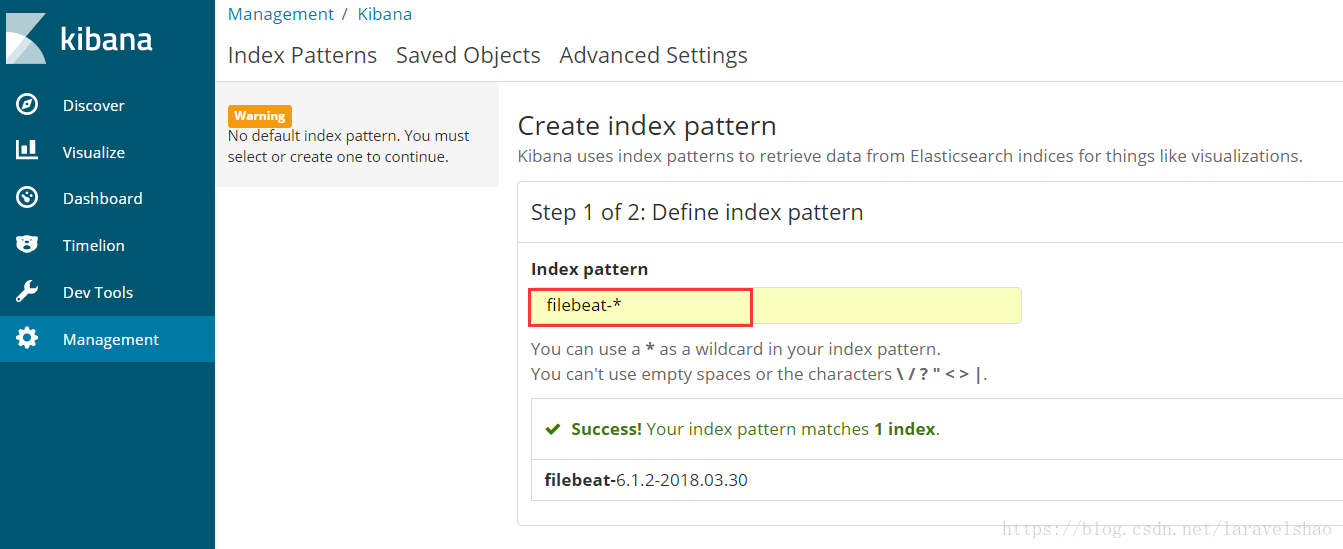
3.返回Discover模块,如下说明添加成功。
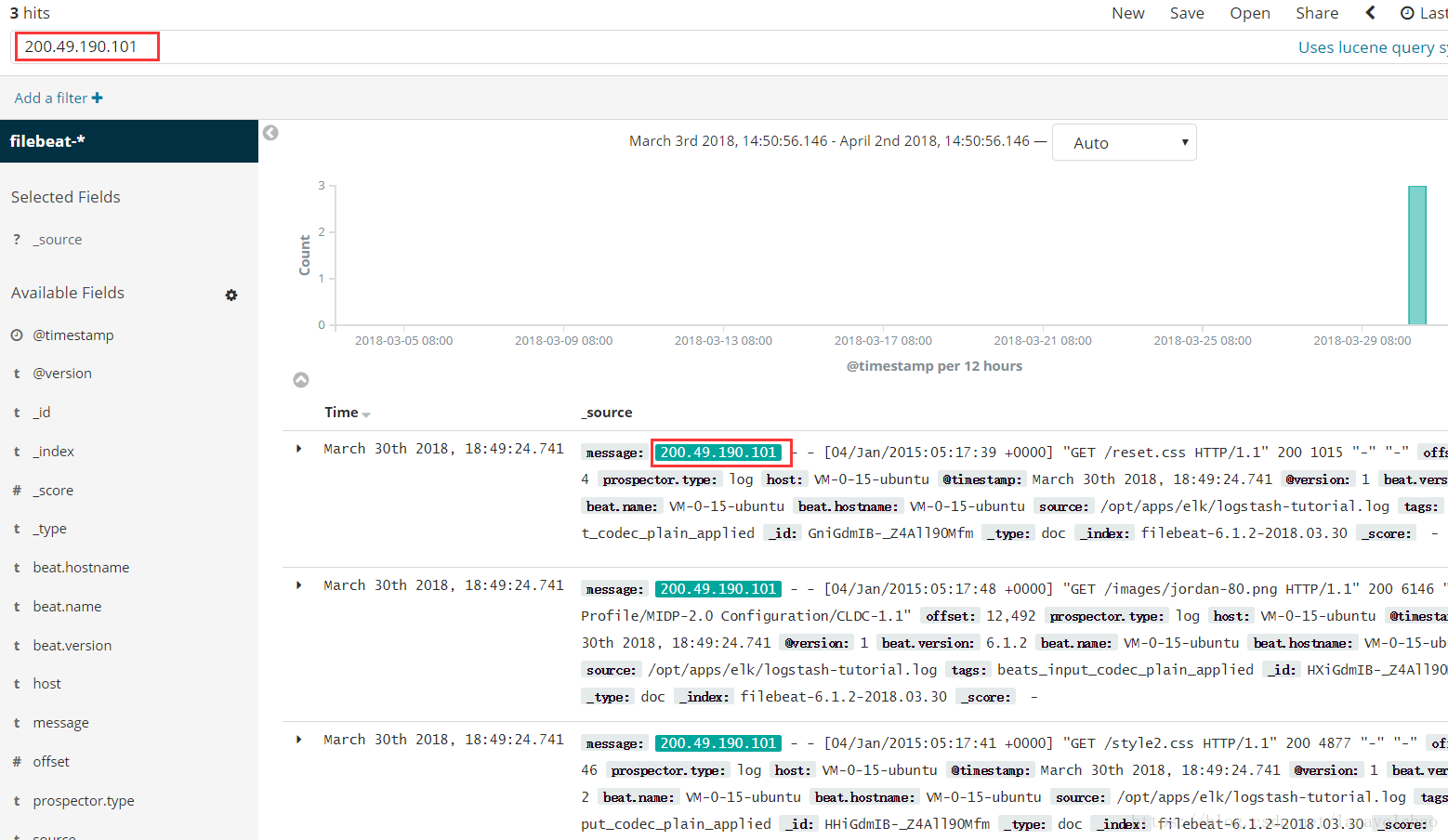
4.在搜索框输入关键字可在当前选择的Index Pattern基础上进行筛选。
5. 参考
基本是按照这位仁兄的博客搭建的,遇到问题搜一搜,基本都能解决